Consistent Hashing
减少 rehash 成本的分片策略
先看要解决的问题。
为什么需要 consistent hashing?
传统 hash 分配通常是:对 partition key(例如 request ID 或 IP)做 hash,再对节点数 N 取模,得到目标 node。
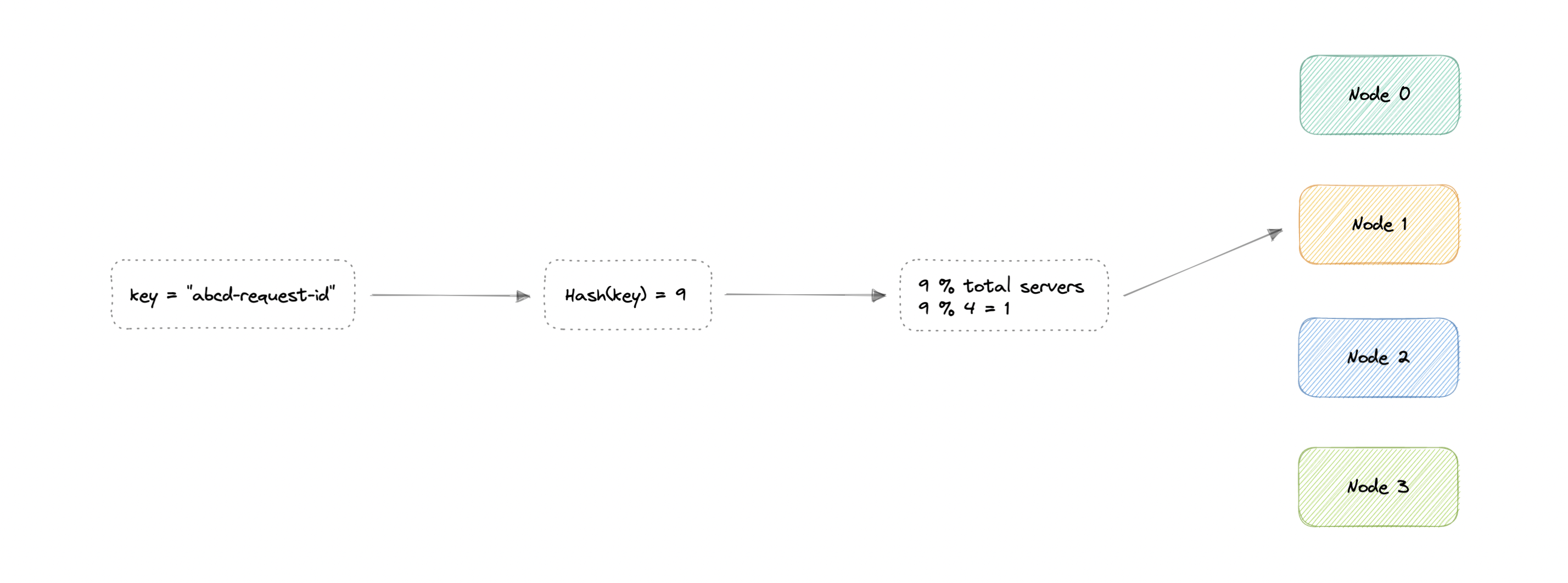
$$ \begin{align*} & Hash(key_1) \to H_1 \bmod N = Node_0 \ & Hash(key_2) \to H_2 \bmod N = Node_1 \ & Hash(key_3) \to H_3 \bmod N = Node_2 \ & ... \ & Hash(key_n) \to H_n \bmod N = Node_{n-1} \end{align*} $$
Where:
key: Request ID 或 IP
H: Hash 函数结果
N: 节点总数
Node: 请求被路由到的节点
问题是:一旦增/减节点,N 改变,映射就全乱,绝大多数请求都要重分配,成本很高。
我们希望请求在 nodes 之间分布均匀,并且增删 nodes 时只需要迁移少量 keys。因此需要一种不直接依赖节点数量的分配方案。
Consistent hashing 解决了这个 horizontal scaling 问题:扩缩容时,不需要 rehash 全部 keys。
How does it work
Consistent Hashing 是一种分布式 hash 方案,把 nodes 映射到一个抽象的 hash ring 上。这样 servers 与 objects 都能 scale,而不影响整体系统。
使用 consistent hashing 时,只有 K/N 的数据需要重分配:
$$ R = K/N $$
Where:
R: 需要重分配的数据量
K: partition keys 数量
N: 节点数量
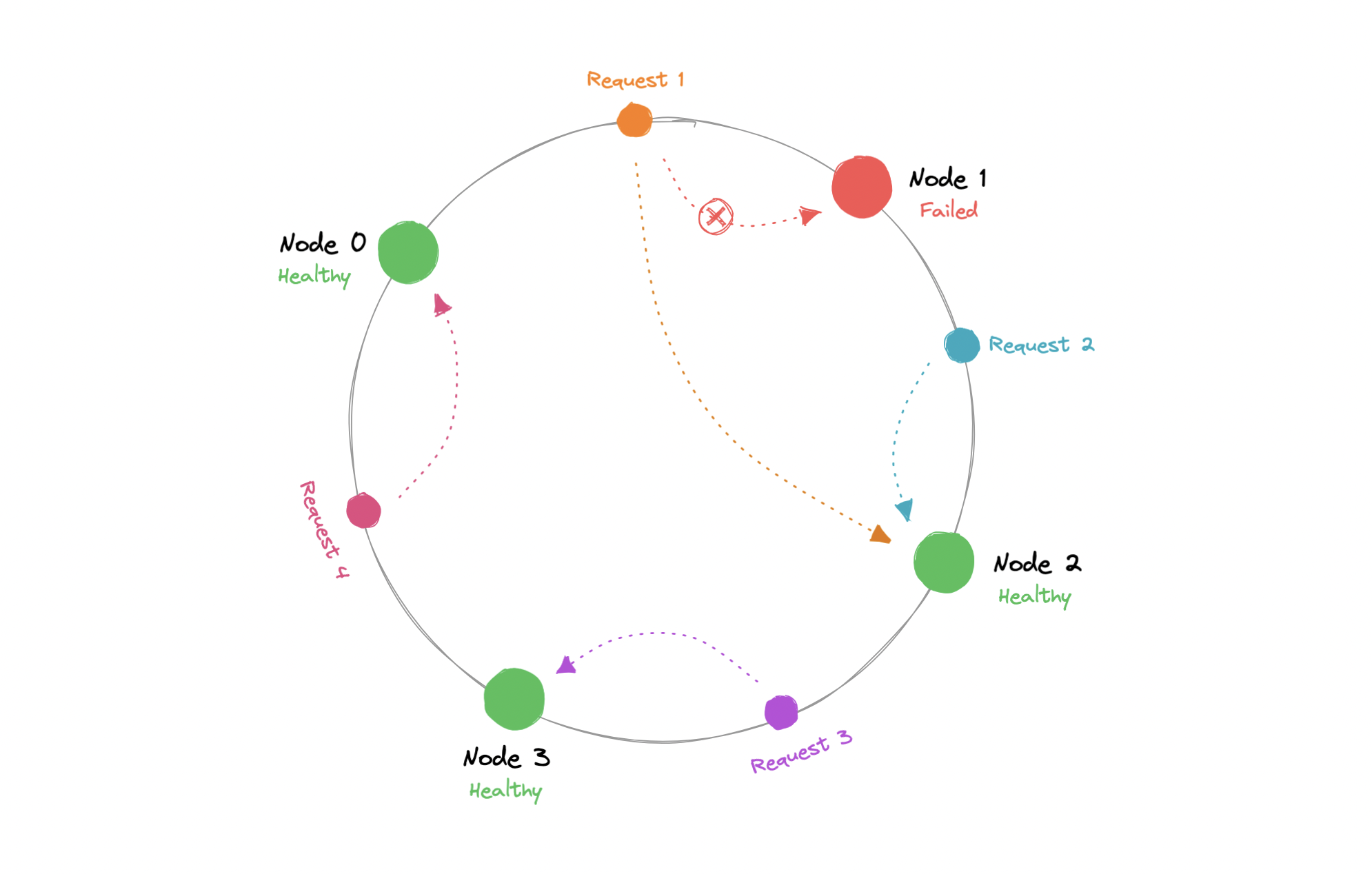
Hash 函数输出一个范围(例如 0...m-1),映射到 hash ring。我们对 request 与 node 都做 hash,把它们放在 ring 上:
$$ \begin{align*} & Hash(key_1) = P_1 \ & Hash(key_2) = P_2 \ & Hash(key_3) = P_3 \ & ... \ & Hash(key_n) = P_{m-1} \end{align*} $$
Where:
key: Request/Node ID 或 IP
P: 在 hash ring 上的位置
m: hash ring 的总范围
当请求进来时,沿着顺时针(或逆时针)方向找到最近的 node 进行路由。新增或移除 node 时,只会影响环上一小段 keys。
理论上 consistent hashing 可以均匀分布负载,但实践中仍可能出现热点(hotspot),导致某个 server 过载。可以通过增加 nodes 缓解,但成本高。
Virtual Nodes
为让负载更均匀,可以引入 virtual node(VNode)。
做法是把 hash range 切成多个小段,每个物理 node 映射多个小段(也就是多个 VNodes),等于把同一物理 node 多次映射到 ring 上。
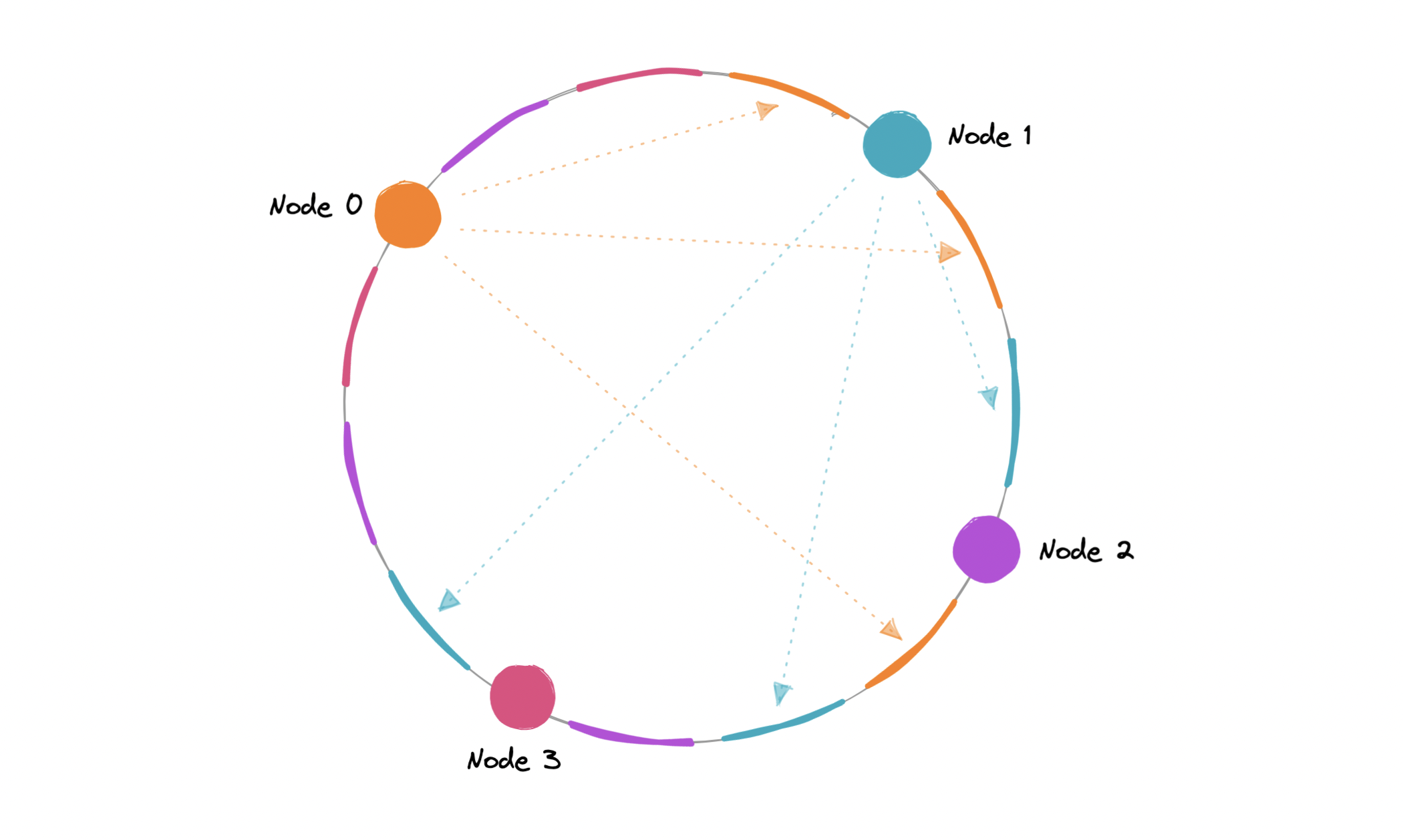
可以用 k 个 hash 函数:
$$ \begin{align*} & Hash_1(key_1) = P_1 \ & Hash_2(key_2) = P_2 \ & Hash_3(key_3) = P_3 \ & . . . \ & Hash_k(key_n) = P_{m-1} \end{align*} $$
Where:
key: Request/Node ID 或 IP
k: hash functions 数量
P: hash ring 上的位置
m: hash ring 总范围
VNode 让负载更均匀,扩缩容后的 rebalancing 更快,也降低 hotspot 概率。
Data Replication
为了高 availability 与 durability,consistent hashing 通常会把每条数据复制到 N 个 nodes 上,这里的 N 就是 replication factor。最终一致系统里,复制通常是异步完成。
Advantages
- 扩缩容更可预测
- 便于 partitioning 与 replication
- 提升 scalability 与 availability
- 减少 hotspot
Disadvantages
- 复杂度上升
- 可能引发 cascading failures
- 负载分布仍可能不均
- 节点临时故障时 key 管理成本高
Examples
- Apache Cassandra 的数据分区
- Amazon DynamoDB 的负载分配