Design Uber
case study: Uber
我们来设计一个类似 Uber 的网约车服务,对标 Lyft、OLA Cabs。
What is Uber?
Uber 是出行平台,用户叫车、司机接单并完成行程,支持 web 与移动端。
Requirements
Functional requirements
两类用户:Customers 与 Drivers。
Customers
- 查看附近车辆、ETA 与价格
- 预约/下单
- 查看司机位置
Drivers
- 接单或拒单
- 查看接客位置
- 到达后完成行程
Non-Functional requirements
- 高 reliability
- 高 availability,低 latency
- 可扩展、高效
Extended requirements
- 评价
- 支付
- Metrics & analytics
Estimation and Constraints
注意:和面试官确认规模假设。
Traffic
假设 100M DAU、1M drivers、10M rides/day。每个用户 10 次动作 => 1B requests/day:
$$ 100 \space million \times 10 \space actions = 1 \space billion/day $$
RPS
$$ \frac{1 \space billion}{(24 \space hrs \times 3600 \space seconds)} = \sim 12K \space requests/second $$
Storage
每条 400 bytes:
$$ 1 \space billion \times 400 \space bytes = \sim 400 \space GB/day $$
10 年约 1.4 PB:
$$ 400 \space GB \times 10 \space years \times 365 \space days = \sim 1.4 \space PB $$
Bandwidth
$$ \frac{400 \space GB}{(24 \space hrs \times 3600 \space seconds)} = \sim 5 \space MB/second $$
High-level estimate
| Type | Estimate |
|---|---|
| Daily active users (DAU) | 100 million |
| Requests per second (RPS) | 12K/s |
| Storage (per day) | ~400 GB |
| Storage (10 years) | ~1.4 PB |
| Bandwidth | ~5 MB/s |
Data model design

customers:用户
drivers:司机
trips:行程
cabs:车辆信息
ratings:评分
payments:支付
选什么 database?
建议拆成多服务,各自拥有表,避免单库瓶颈。可用 PostgreSQL 或 Apache Cassandra。
API design
Request a Ride
requestRide(customerID: UUID, source: Tuple<float>, destination: Tuple<float>, cabType: Enum<string>, paymentMethod: Enum<string>): Ride
Cancel the Ride
cancelRide(customerID: UUID, reason?: string): boolean
Accept / Deny
acceptRide(driverID: UUID, rideID: UUID): boolean
denyRide(driverID: UUID, rideID: UUID): boolean
Start / End Trip
startTrip(driverID: UUID, tripID: UUID): boolean
endTrip(driverID: UUID, tripID: UUID): boolean
Rate the Trip
rateTrip(customerID: UUID, tripID: UUID, rating: int, feedback?: string): boolean
High-level design
Architecture
采用 microservices:
Customer Service:客户信息
Driver Service:司机信息
Ride Service:匹配 + quadtree
Trip Service:行程管理
Payment Service:支付
Notification Service:通知
Analytics Service:指标分析
Inter-service communication
REST/HTTP 或 gRPC,配合 Service discovery。
How it works
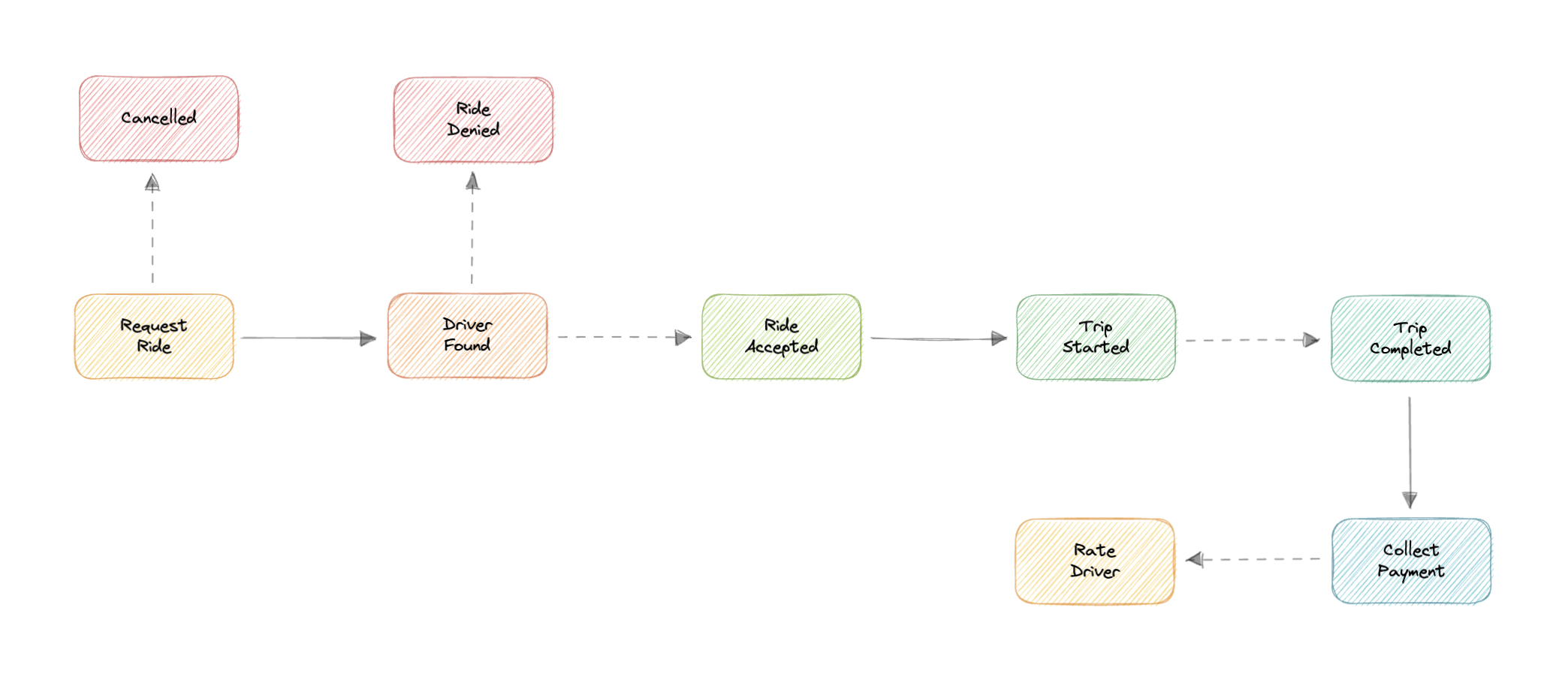
- 用户发起请求
- Ride service 找附近司机 + ETA
- 广播给司机
- 司机接单后推送位置
- 开始行程
- 完成行程并收款
- 用户评价
Location Tracking
Pull model:Long polling
Push model:WebSockets / SSE(推荐 WebSockets)
后台需有 GPS ping。
Ride Matching
SQL:范围查询,scale 差
Geohashing:用 geohash 索引
Quadtrees:范围查询高效
结合 Redis 缓存位置。用 Hilbert curve 提升 range query。
Race conditions
用 Mutex + transactions 保障一致性。
Best drivers
按 rating/反馈做排序。
High demand
用 Surge Pricing。
Payments
Notifications
用 Kafka / message queue + FCM/APNS。
Detailed design
Data Partitioning
按区域/分片存储,配合 Sharding + Consistent hashing。
Metrics and Analytics
Caching
缓存司机/乘客位置,LRU eviction。
Identify and resolve bottlenecks
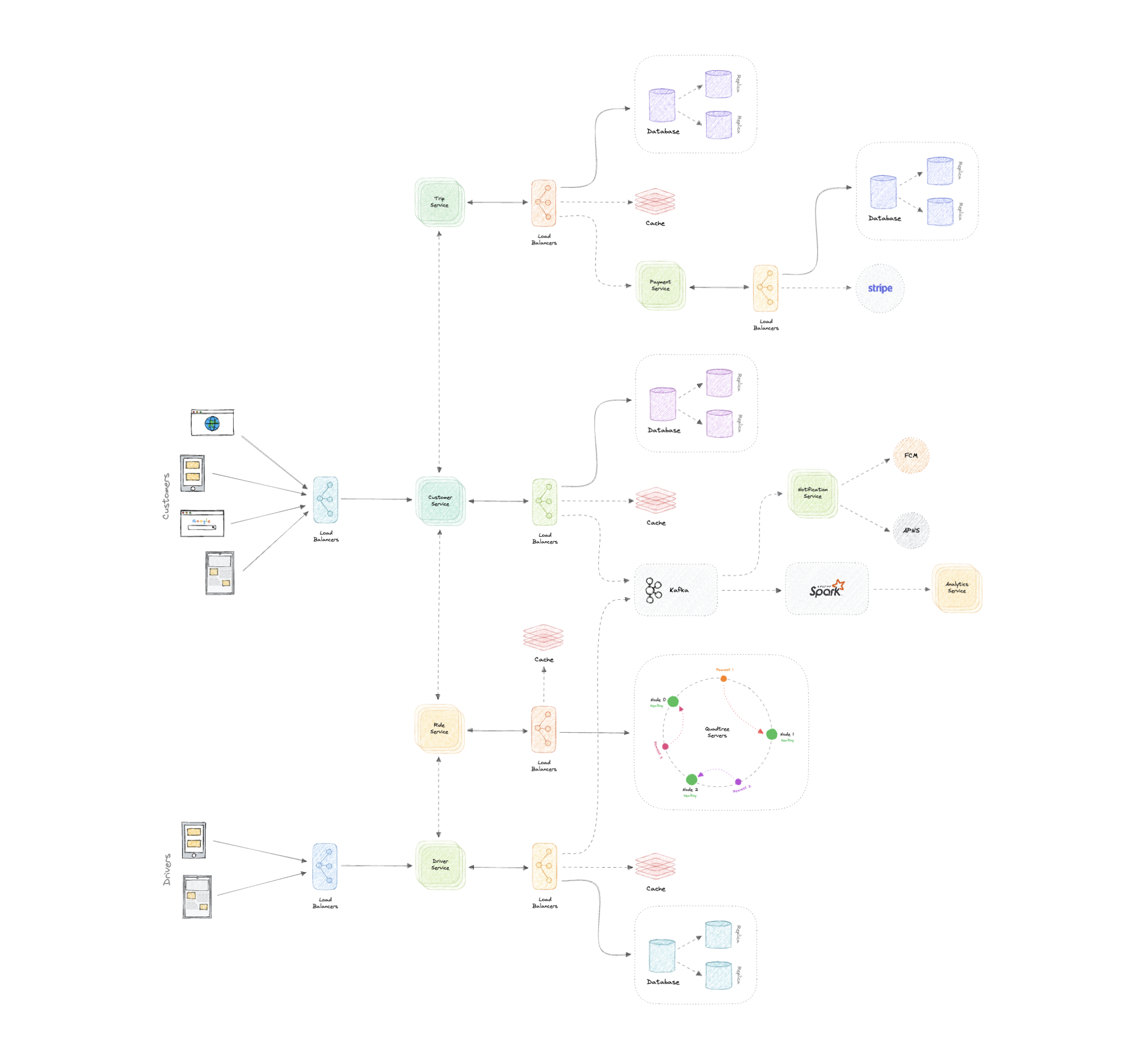
提升 resilience:多实例、load balancers、DB replicas、分布式 cache 多副本、Kafka/NATS。